Deepseekの驚くほど安価なAIモデルは、業界の巨人に挑戦しています。中国のスタートアップのDeepSeek V3は、マルチトークン予測(MTP)、256のニューラルネットワークを利用した専門家(MOE)の混合、およびマルチヘッド潜在的注意(MLA)などの革新的な技術を誇り、2048を使用してわずか600万ドルのトレーニングコストを主張しました。 GPU。しかし、この一見低い数値は、複数のデータセンターにわたって約50,000のNVIDIA GPU(H800、H100、およびH20ユニットを含む)の大規模なインフラストラクチャを明らかにしているセミアンアリシスの発見とはっきりと対照的であり、サーバーの総投資と約16億ドルおよび運用費用を表します。 9億4,400万ドル。
 画像:Ensigame.com
画像:Ensigame.com
 画像:Ensigame.com
画像:Ensigame.com
High-Flyer Hedge Fundの子会社であるDeepseekは、データセンターを所有しており、迅速な革新と最適化を促進しています。その自己資金の性質と高い給与(一部の研究者は年間130万ドル以上を稼いでいます)を中国の才能を引き付け、その成功に貢献しています。最初の600万ドルの数値は、トレーニング前のGPUコストのみを反映しており、調査、改良、データ処理、インフラ費用を省略しています。 DeepseekのAI開発への実際の投資は5億ドルを超えています。この多大な投資にもかかわらず、その無駄のない構造は、より大きく、より官僚的な競合他社と比較して効率的なイノベーションを可能にします。
 画像:Ensigame.com
画像:Ensigame.com
 画像:Ensigame.com
画像:Ensigame.com
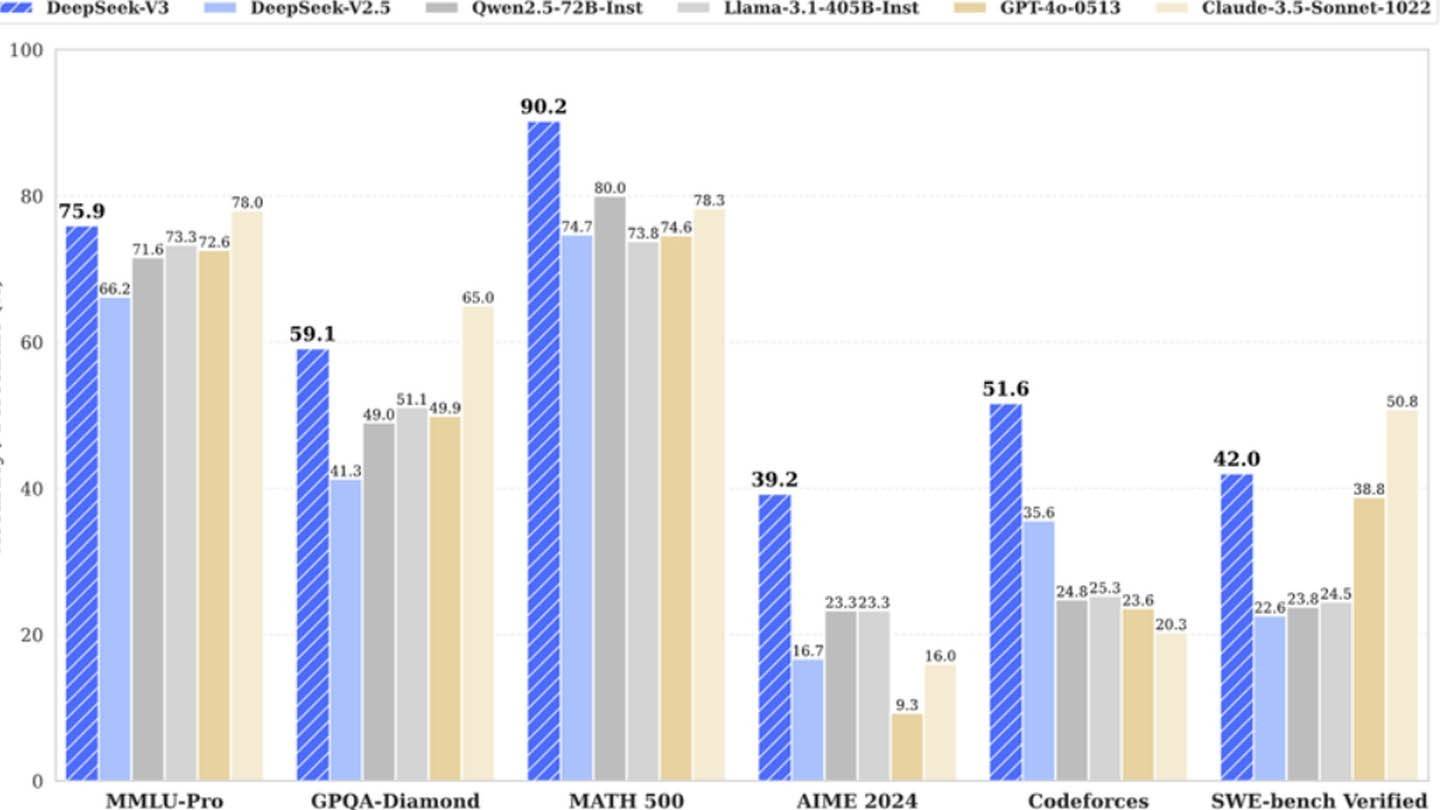
Deepseekの「革新的な予算」請求は間違いなく膨らんでいますが、その成功は、資金提供された独立したAI企業の競争の可能性を強調しています。トレーニングコストを比較するとコントラストが厳しくなります。DeepSeekのR1の価格は500万ドルで、ChatGPT-4は1億ドルの費用がかかり、DeepSeekの相対的な費用対効果を強調しています。