El modelo de IA sorprendentemente económico de Deepseek desafía a los gigantes de la industria. The Chinese startup's DeepSeek V3, boasting innovative technologies like Multi-token Prediction (MTP), Mixture of Experts (MoE) utilizing 256 neural networks, and Multi-head Latent Attention (MLA), initially claimed a training cost of just $6 million using 2048 GPU. Sin embargo, esta cifra aparentemente baja contrasta fuertemente con los hallazgos de semianálisis que revelan una infraestructura masiva de aproximadamente 50,000 GPU NVIDIA (incluidas H800, H100 y H20 unidades) en múltiples centros de datos, lo que representa una inversión de servidor total de aproximadamente $ 1.6 mil millones y gastos operativos cercanos cercanos a $ 944 millones.
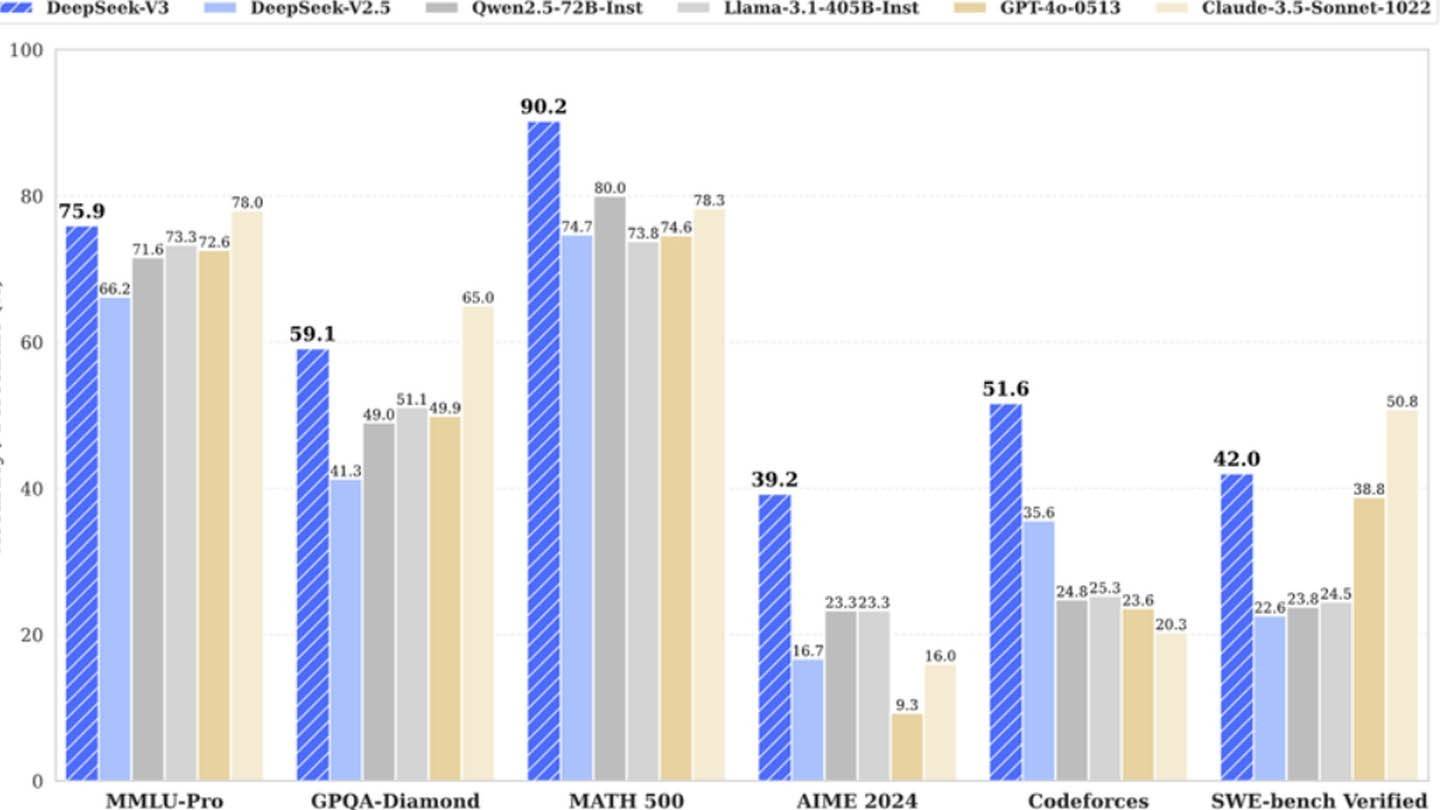 Imagen: Ensigame.com
Imagen: Ensigame.com
 Imagen: Ensigame.com
Imagen: Ensigame.com
Deepseek, una subsidiaria de High-Flyer Hedge Fund, posee sus centros de datos, fomentando una rápida innovación y optimización. Su naturaleza autofinanciada y su altos salarios (algunos investigadores ganan más de $ 1.3 millones anuales) atraen el mejor talento chino, contribuyendo a su éxito. La cifra inicial de $ 6 millones solo refleja los costos de GPU previos al entrenamiento, omitiendo la investigación, el refinamiento, el procesamiento de datos y los gastos de infraestructura. La inversión real de Deepseek en el desarrollo de IA supera los $ 500 millones. A pesar de esta importante inversión, su estructura magra permite una innovación eficiente en comparación con competidores más grandes y burocráticos.
 Imagen: Ensigame.com
Imagen: Ensigame.com
 Imagen: Ensigame.com
Imagen: Ensigame.com
Si bien el reclamo de "presupuesto revolucionario" de Deepseek está posiblemente inflado, su éxito destaca el potencial competitivo de una compañía de IA independiente bien financiada. El contraste es marcado al comparar los costos de capacitación: R1 de Deepseek costó $ 5 millones, mientras que ChatGPT-4 costó $ 100 millones, lo que subraya la rentabilidad relativa de Deepseek, incluso con su inversión general sustancial.