Deepseeks überraschend kostengünstige KI -Modell stellt die Branchenriesen heraus. Das Deepseek V3 des chinesischen Startups mit innovativen Technologien wie Multi-Soury Prediction (MTP), Mischung aus Experten (MOE) unter Verwendung von 256 neuronalen Netzwerken und latentem Multi-Head-Aufmerksamkeit (MLA) beanspruchte zunächst die Schulungskosten von nur 6 Millionen US-Dollar mit 2048. GPUS. Diese scheinbar niedrige Zahl steht jedoch stark zu den Ergebnissen der semianalyse, die eine massive Infrastruktur von ungefähr 50.000 NVIDIA -GPUs (einschließlich H800, H100 und H20 -Einheiten) in mehreren Rechenzentren ergeben, was eine Gesamtinvestition von rund 1,6 Milliarden US 944 Millionen Dollar.
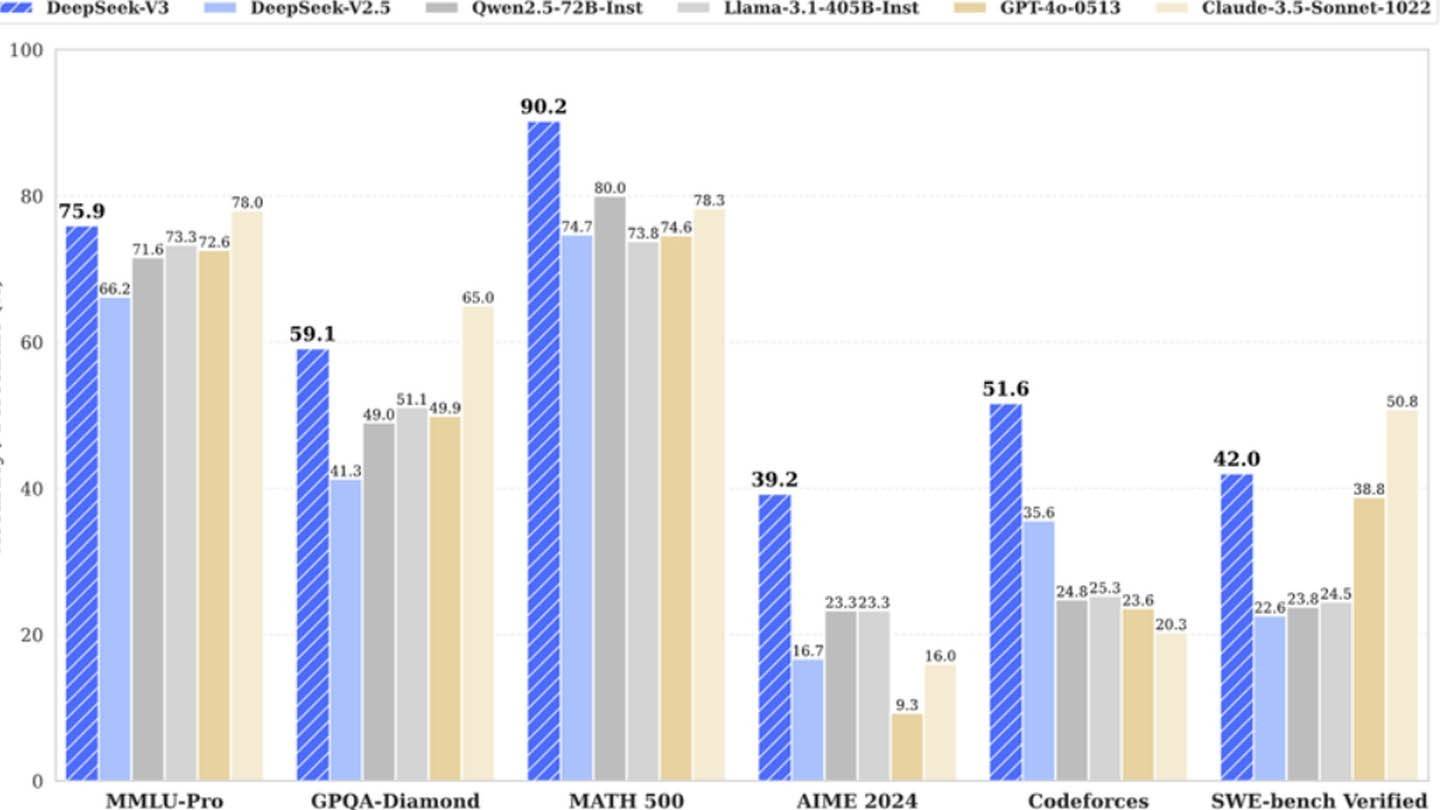 Bild: Ensigame.com
Bild: Ensigame.com
 Bild: Ensigame.com
Bild: Ensigame.com
Deepseek, eine Tochtergesellschaft von High-Flyer Hedgefonds, besitzt seine Rechenzentren und fördert schnelle Innovation und Optimierung. Seine selbstfinanzierte Natur und hohe Gehälter (einige Forscher verdienen jährlich über 1,3 Millionen US-Dollar) ziehen erstklassiges chinesisches Talent an und tragen zu ihrem Erfolg bei. Die anfängliche Zahl in Höhe von 6 Mio. USD spiegelt nur die GPU-Kosten vor dem Training und die Auslassung von Forschung, Verfeinerung, Datenverarbeitung und Infrastrukturausgaben wider. Die tatsächliche Investition von Deepseek in die KI -Entwicklung übersteigt 500 Millionen US -Dollar. Trotz dieser bedeutenden Investitionen ermöglicht seine magere Struktur effiziente Innovationen im Vergleich zu größeren, bürokratischeren Wettbewerbern.
 Bild: Ensigame.com
Bild: Ensigame.com
 Bild: Ensigame.com
Bild: Ensigame.com
Während Deepseeks "revolutionäres Budget" -Anspruch wohl aufgeblasen wird, unterstreicht sein Erfolg das Wettbewerbspotential eines gut finanzierten, unabhängigen KI-Unternehmens. Der Kontrast ist im Vergleich der Schulungskosten stark: Deepseeks R1 kostete 5 Millionen US-Dollar, während Chatgpt-4 Berichten zufolge 100 Millionen US-Dollar kosten und Deepseeks relative Kosteneffizienz auch mit seiner erheblichen Gesamtinvestition unterstreicht.