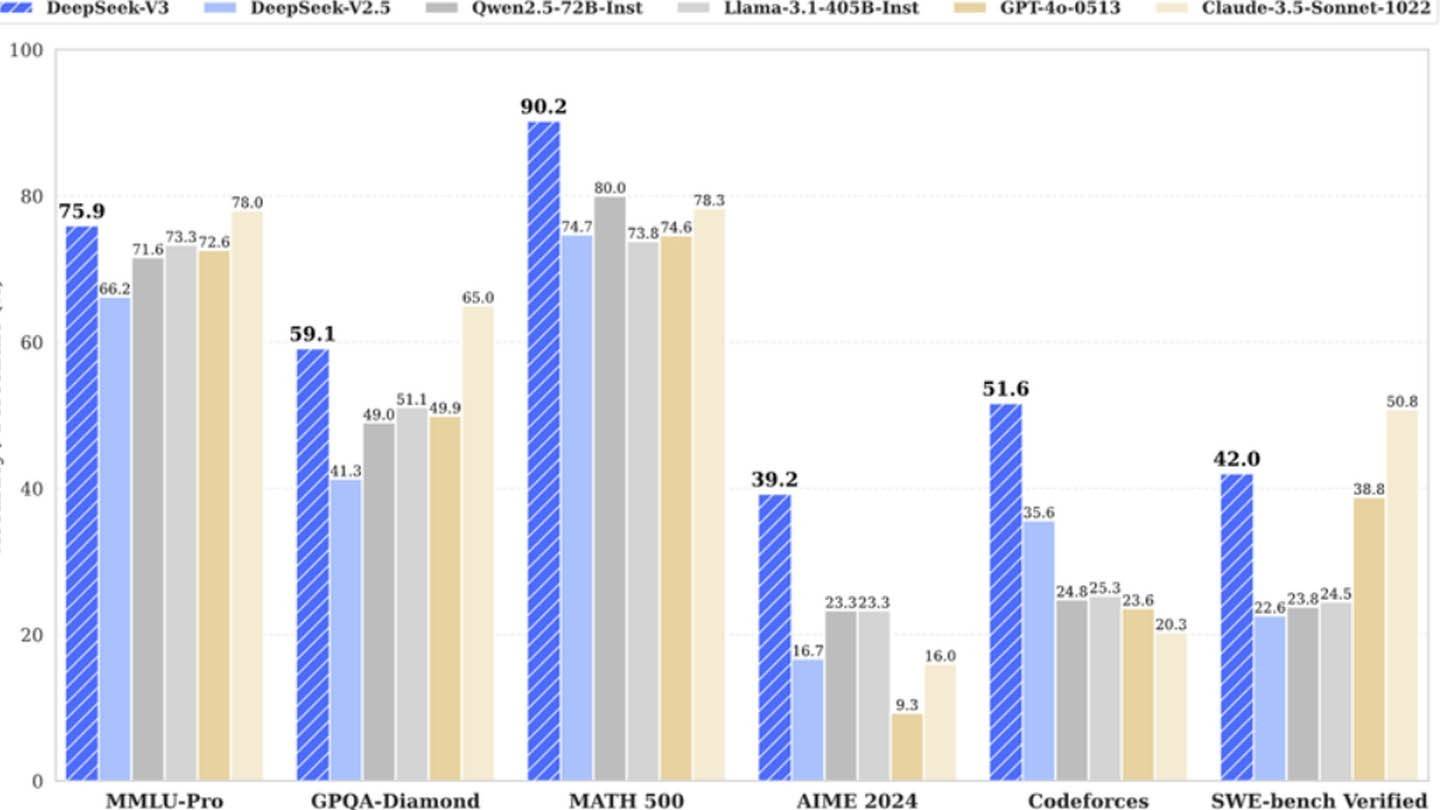
Zaskakująco niedrogi model AI Deepseek wyzwala gigantów branżowych. Deepseek V3 z chińskiego startupu, pochwający innowacyjne technologie, takie jak prognoza wielofunkcyjna (MTP), mieszanka ekspertów (MOE) wykorzystujących 256 sieci neuronowych i wielogodne ukrytą uwagę (MLA), początkowo domagał się kosztu szkolenia zaledwie 6 milionów dolarów przy użyciu 2048 GPU. Ta pozornie niska liczba jednak gwałtownie kontrastuje z ustaleniami Semianalysis, ujawniając ogromną infrastrukturę około 50 000 GPU NVIDIA (w tym jednostki H800, H100 i H20) w wielu centrach danych, reprezentując całkowitą inwestycję serwera wynoszącą około 1,6 miliarda USD i wydatków operacyjnych w pobliżu wydatków operacyjnych w pobliżu wydatków operacyjnych. 944 miliony dolarów.
 Obraz: engame.com
Obraz: engame.com
 Obraz: engame.com
Obraz: engame.com
Deepseek, spółka zależna od funduszu hedgingowego o wysokiej zawartości flyer, jest właścicielem swoich centrów danych, wspierając szybkie innowacje i optymalizację. Jego finansowana natura i wysokie pensje (niektórzy badacze zarabiają ponad 1,3 miliona dolarów rocznie) przyciągają najwyższe chińskie talenty, przyczyniając się do jego sukcesu. Początkowa liczba 6 mln USD odzwierciedla jedynie koszty GPU przed treningiem, pomijając badania, udoskonalanie, przetwarzanie danych i wydatki na infrastrukturę. Rzeczywista inwestycja Deepseek w rozwój AI przekracza 500 milionów dolarów. Pomimo tej znaczącej inwestycji jego szczupła struktura pozwala na wydajne innowacje w porównaniu z większymi, bardziej biurokratycznymi konkurentami.
 Obraz: engame.com
Obraz: engame.com
 Obraz: engame.com
Obraz: engame.com
Podczas gdy roszczenie Deepseek „rewolucyjne budżet” jest prawdopodobnie zawyżone, jego sukces podkreśla potencjał konkurencyjny dobrze finansowanej, niezależnej firmy AI. Kontrast jest wyraźny przy porównywaniu kosztów szkolenia: R1 Deepseek kosztował 5 milionów dolarów, podczas gdy Chatgpt-4 podobno kosztował 100 milionów dolarów, podkreślając względną opłacalność Deepeek, nawet przy znacznej ogólnej inwestycji.





























