DeepSeek's surprisingly inexpensive AI model challenges industry giants. The Chinese startup's DeepSeek V3, boasting innovative technologies like Multi-token Prediction (MTP), Mixture of Experts (MoE) utilizing 256 neural networks, and Multi-head Latent Attention (MLA), initially claimed a training cost of just $6 million using 2048 GPUs. This seemingly low figure, however, contrasts sharply with SemiAnalysis' findings revealing a massive infrastructure of approximately 50,000 Nvidia GPUs (including H800, H100, and H20 units) across multiple data centers, representing a total server investment of roughly $1.6 billion and operational expenses near $944 million.
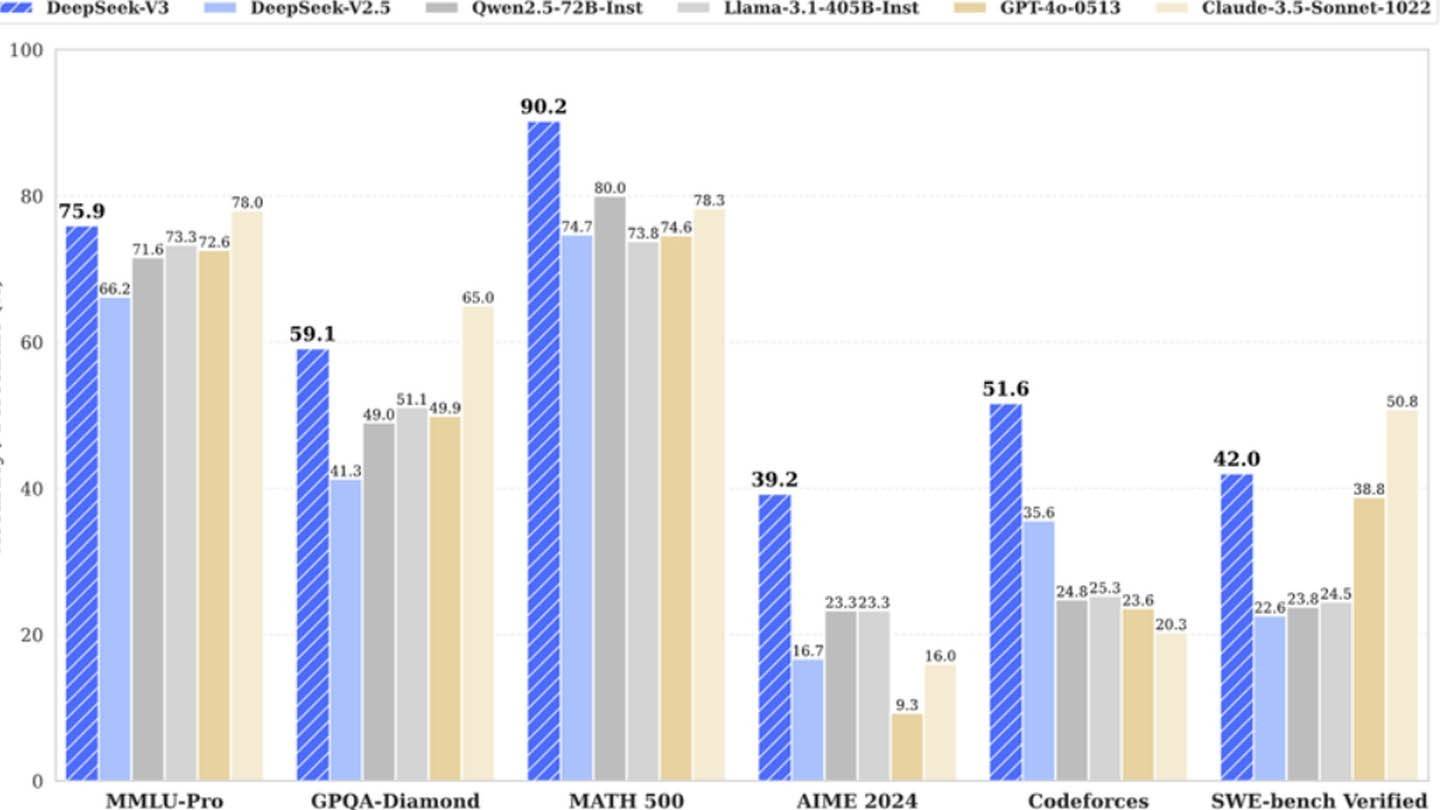 Image: ensigame.com
Image: ensigame.com
 Image: ensigame.com
Image: ensigame.com
DeepSeek, a subsidiary of High-Flyer hedge fund, owns its data centers, fostering rapid innovation and optimization. Its self-funded nature and high salaries (some researchers earn over $1.3 million annually) attract top Chinese talent, contributing to its success. The initial $6 million figure only reflects pre-training GPU costs, omitting research, refinement, data processing, and infrastructure expenses. DeepSeek's actual investment in AI development exceeds $500 million. Despite this significant investment, its lean structure allows for efficient innovation compared to larger, more bureaucratic competitors.
 Image: ensigame.com
Image: ensigame.com
 Image: ensigame.com
Image: ensigame.com
While DeepSeek's "revolutionary budget" claim is arguably inflated, its success highlights the competitive potential of a well-funded, independent AI company. The contrast is stark when comparing training costs: DeepSeek's R1 cost $5 million, while ChatGPT-4 reportedly cost $100 million, underscoring DeepSeek's relative cost-effectiveness, even with its substantial overall investment.