Il modello AI sorprendentemente economico di Deepseek sfida i giganti del settore. Deepseek V3 della startup cinese, che vanta tecnologie innovative come la previsione multi-token (MTP), la miscela di esperti (MOE) utilizzando 256 reti neurali e l'attenzione latente multi-testa (MLA), ha inizialmente affermato un costo di formazione di soli $ 6 milioni utilizzando 2048 usando 2048 GPU. Questa cifra apparentemente bassa, tuttavia, contrasta nettamente con i risultati della semianalisi che rivelano una massiccia infrastruttura di circa 50.000 GPU NVIDIA (tra cui H800, H100 e unità H20) su più data center, che rappresenta un investimento in totale server di circa $ 1,6 miliardi e spese operative vicino $ 944 milioni.
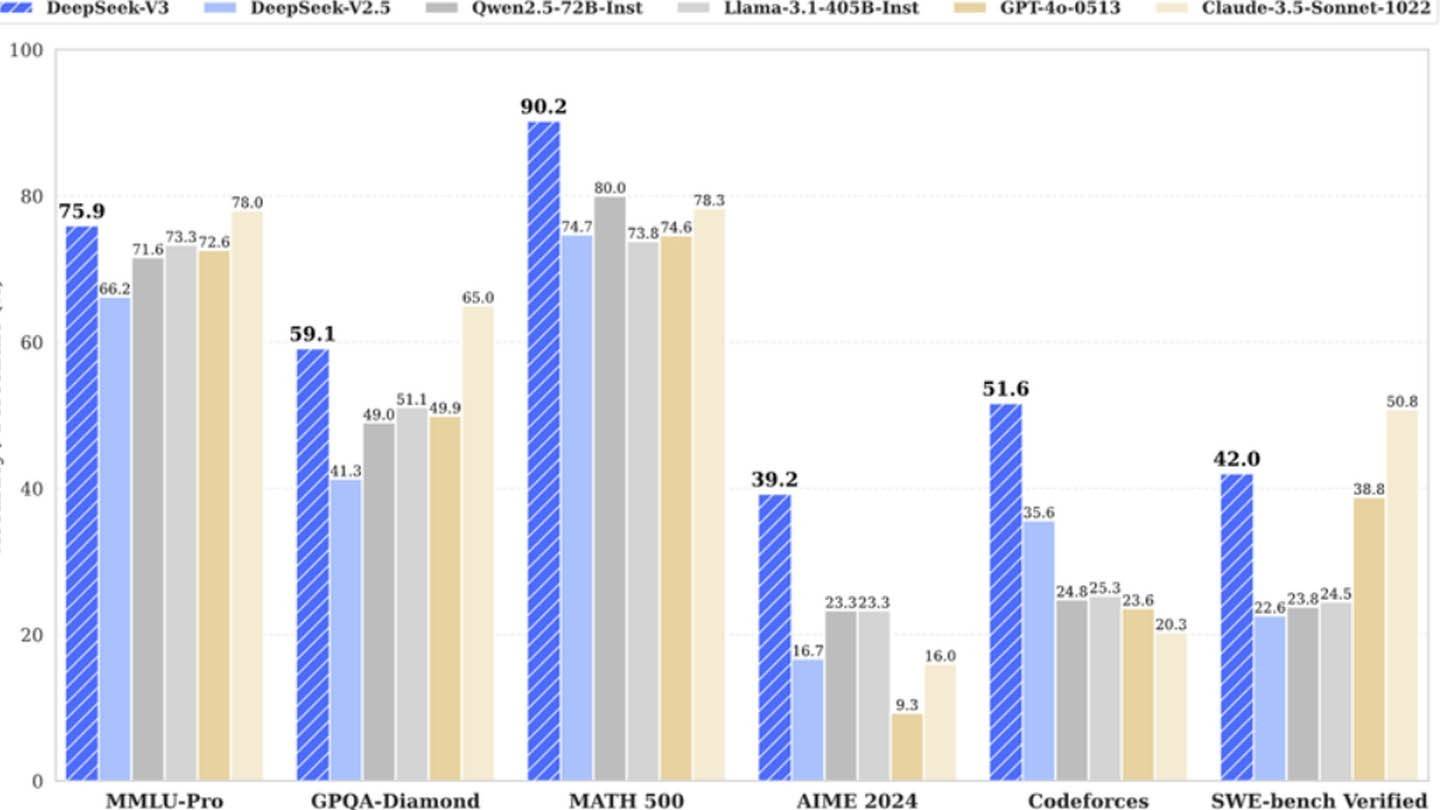 Immagine: Ensigame.com
Immagine: Ensigame.com
 Immagine: Ensigame.com
Immagine: Ensigame.com
DeepSeek, una consociata di hedge fund ad alto frigo, possiede i suoi data center, promuovendo una rapida innovazione e ottimizzazione. La sua natura autofinanziata e gli alti salari (alcuni ricercatori guadagnano oltre $ 1,3 milioni all'anno) attirano i migliori talenti cinesi, contribuendo al suo successo. La cifra iniziale di 6 milioni di dollari riflette solo i costi della GPU pre-allenamento, omettere la ricerca, la raffinatezza, l'elaborazione dei dati e le spese di infrastruttura. L'effettivo investimento di Deepseek nello sviluppo dell'IA supera i $ 500 milioni. Nonostante questo significativo investimento, la sua struttura snella consente un'innovazione efficiente rispetto ai concorrenti più grandi e burocratici.
 Immagine: Ensigame.com
Immagine: Ensigame.com
 Immagine: Ensigame.com
Immagine: Ensigame.com
Mentre l'affermazione del "bilancio rivoluzionario" di Deepseek è probabilmente gonfiata, il suo successo evidenzia il potenziale competitivo di una società di intelligenza artificiale ben finanziata e indipendente. Il contrasto è netto quando si confronta i costi di formazione: R1 di Deepseek costa $ 5 milioni, mentre secondo quanto riferito CHATGPT-4 costò $ 100 milioni, sottolineando il rapporto costo-efficacia relativo di Deepseek, anche con il suo sostanziale investimento complessivo.





























