Deepseek's verrassend goedkope AI -model daagt reuzen uit de industrie uit. De Deepseek V3 van de Chinese startup met innovatieve technologieën zoals multi-token voorspelling (MTP), mix van experts (MOE) met 256 neurale netwerken en multi-head latente aandacht (MLA), claimde aanvankelijk een trainingskosten van slechts $ 6 miljoen met 2048 GPU's. Dit schijnbaar lage cijfer contrasteert echter scherp met de bevindingen van Semianysis die een enorme infrastructuur onthullen van ongeveer 50.000 NVIDIA GPU's (inclusief H800, H100 en H20 -eenheden) over meerdere datacenters, die een totale serverinvestering vertegenwoordigen van ongeveer $ 1,6 miljard en operationele kosten in de buurt $ 944 miljoen.
 afbeelding: ensigame.com
afbeelding: ensigame.com
 afbeelding: ensigame.com
afbeelding: ensigame.com
Deepseek, een dochteronderneming van high-flyer hedgefonds, bezit zijn datacenters en bevordert snelle innovatie en optimalisatie. Zijn zelf gefinancierde aard en hoge salarissen (sommige onderzoekers verdienen jaarlijks meer dan $ 1,3 miljoen) trekken top Chinees talent aan, wat bijdraagt aan zijn succes. Het initiële cijfer van $ 6 miljoen weerspiegelt alleen PRPU-kosten voor de training, het weglaten van onderzoek, verfijning, gegevensverwerking en infrastructuurkosten. De werkelijke investering van Deepseek in AI -ontwikkeling is groter dan $ 500 miljoen. Ondanks deze significante investering zorgt de magere structuur voor efficiënte innovatie in vergelijking met grotere, meer bureaucratische concurrenten.
 afbeelding: ensigame.com
afbeelding: ensigame.com
 afbeelding: ensigame.com
afbeelding: ensigame.com
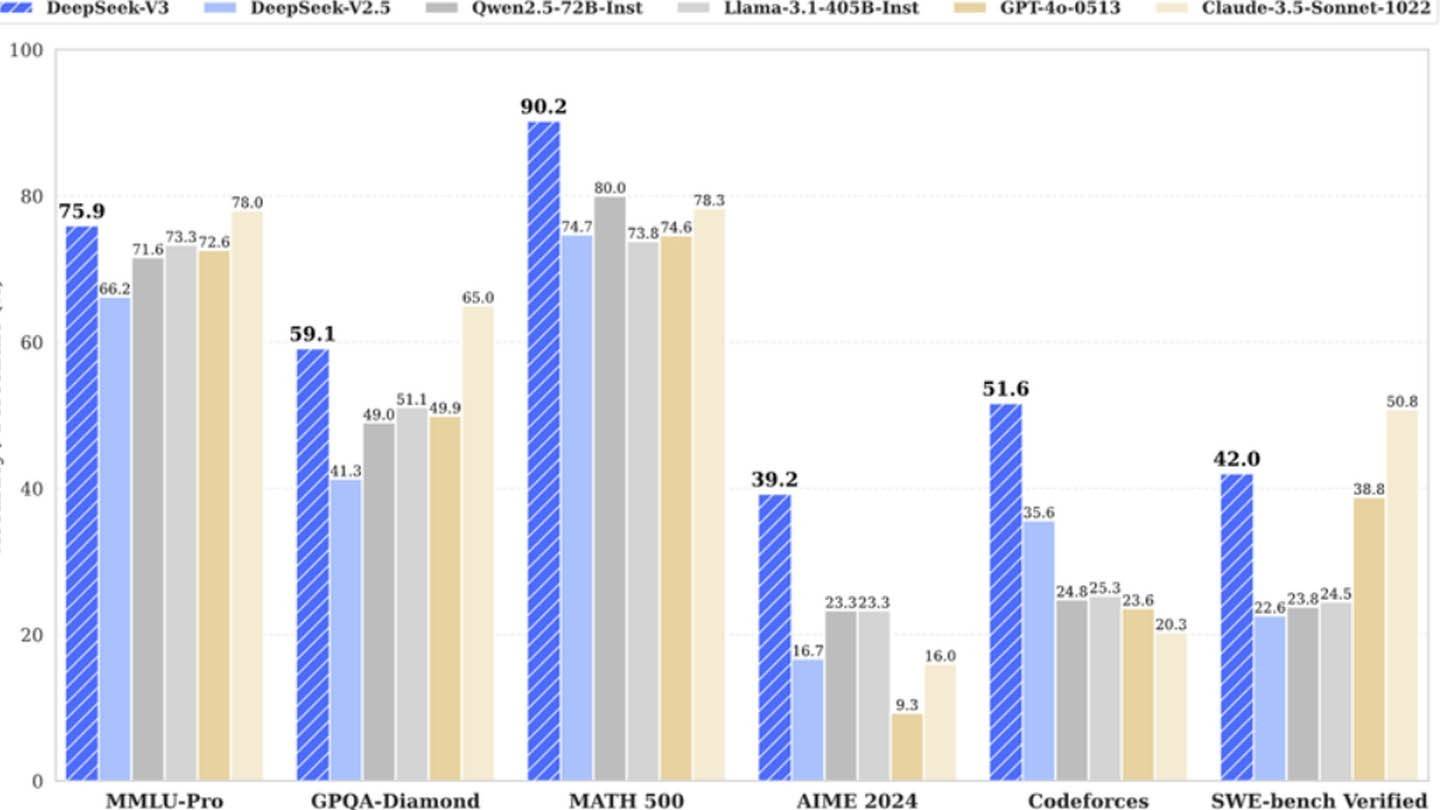
Hoewel de claim "revolutionaire budget" van Deepseek aantoonbaar is opgeblazen, benadrukt het succes het concurrentiepotentieel van een goed gefinancierd, onafhankelijk AI-bedrijf. Het contrast is grimmig bij het vergelijken van trainingskosten: de R1 van Deepseek kost $ 5 miljoen, terwijl Chatgpt-4 naar verluidt $ 100 miljoen kostte, waarbij de relatieve kosteneffectiviteit van Deepseek onderstreept, zelfs met zijn substantiële algehele investeringen.





























